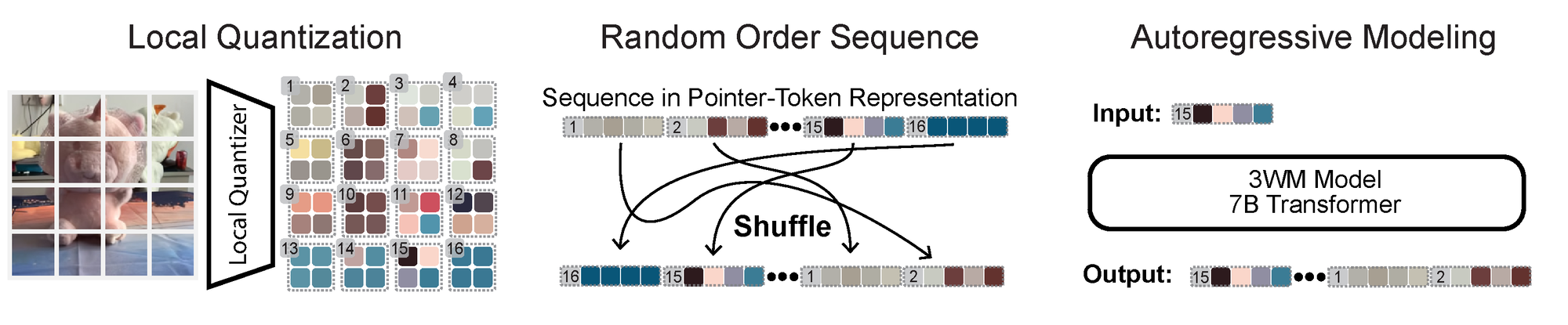
Local Random Access Sequence Modeling makes the PGM tractable. We treat visual data as nodes in a probabilistic graphical model (PGM), but learning such a PGM directly is intractable. To make it practical and scalable, we implement it as a GPT-style next-token predictor through three key components: (a) a local quantizer — a small convolutional autoencoder that produces patch codes with strict patch independence; (b) a pointer-content representation that interleaves pointer and value tokens, letting the model condition on, query, and update arbitrary spatial regions in any order; and (c) an LLM-like autoregressive transformer trained on random traversals of the graph. Together, these let us phrase a wide range of 3D tasks as prompts, without task-specific heads, losses, or datasets, while keeping precise patch-level control.

Optical flow as a control surface. Optical-flow patches serve as a control mechanism within the graphical model, where flow is an intermediate action space: each patch specifies what moves and by how much at that spatial location. With this flexible design, we realize several inference pathways over the same model:
Each capability is a different conditional query over the same joint distribution.
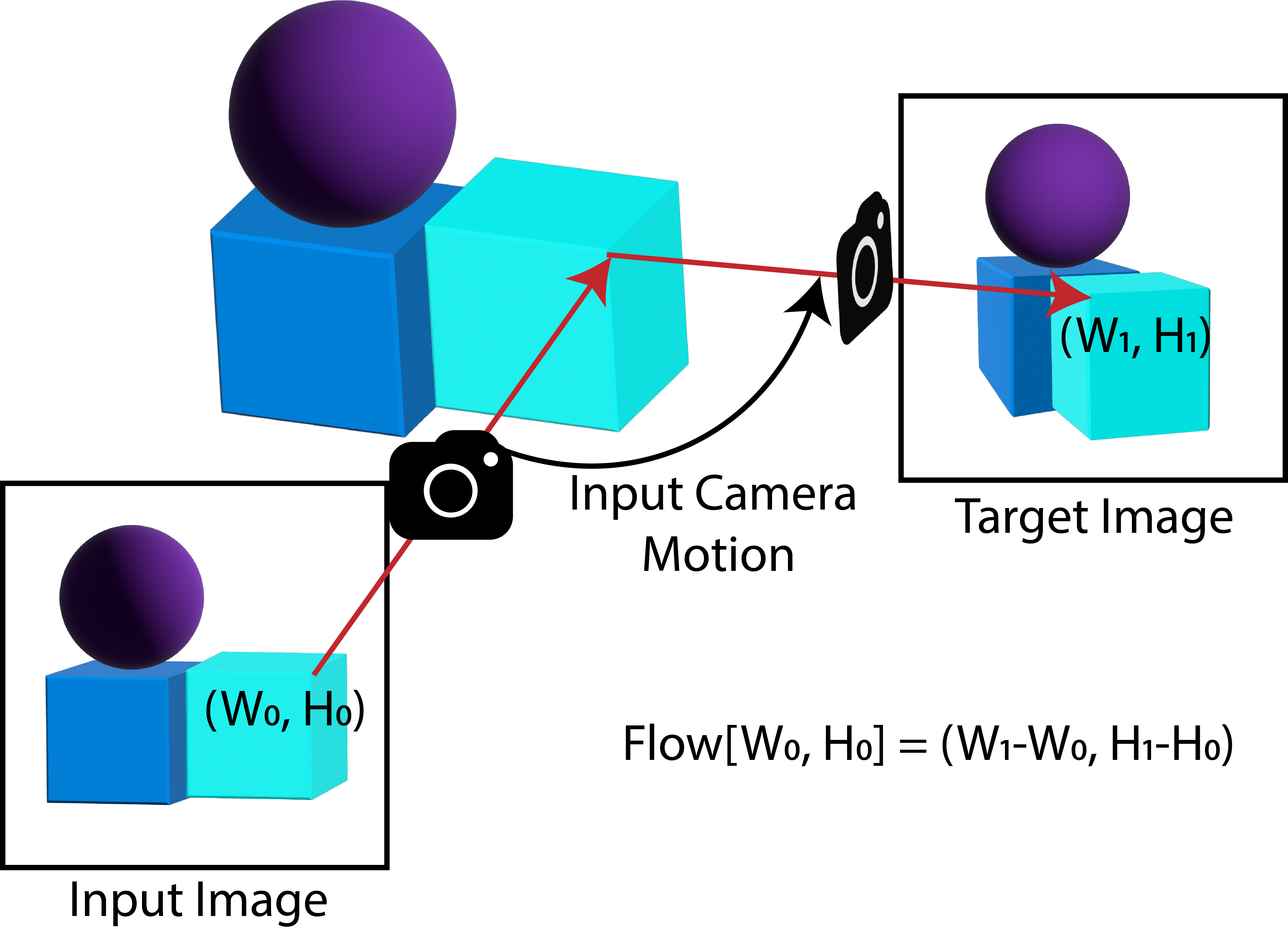
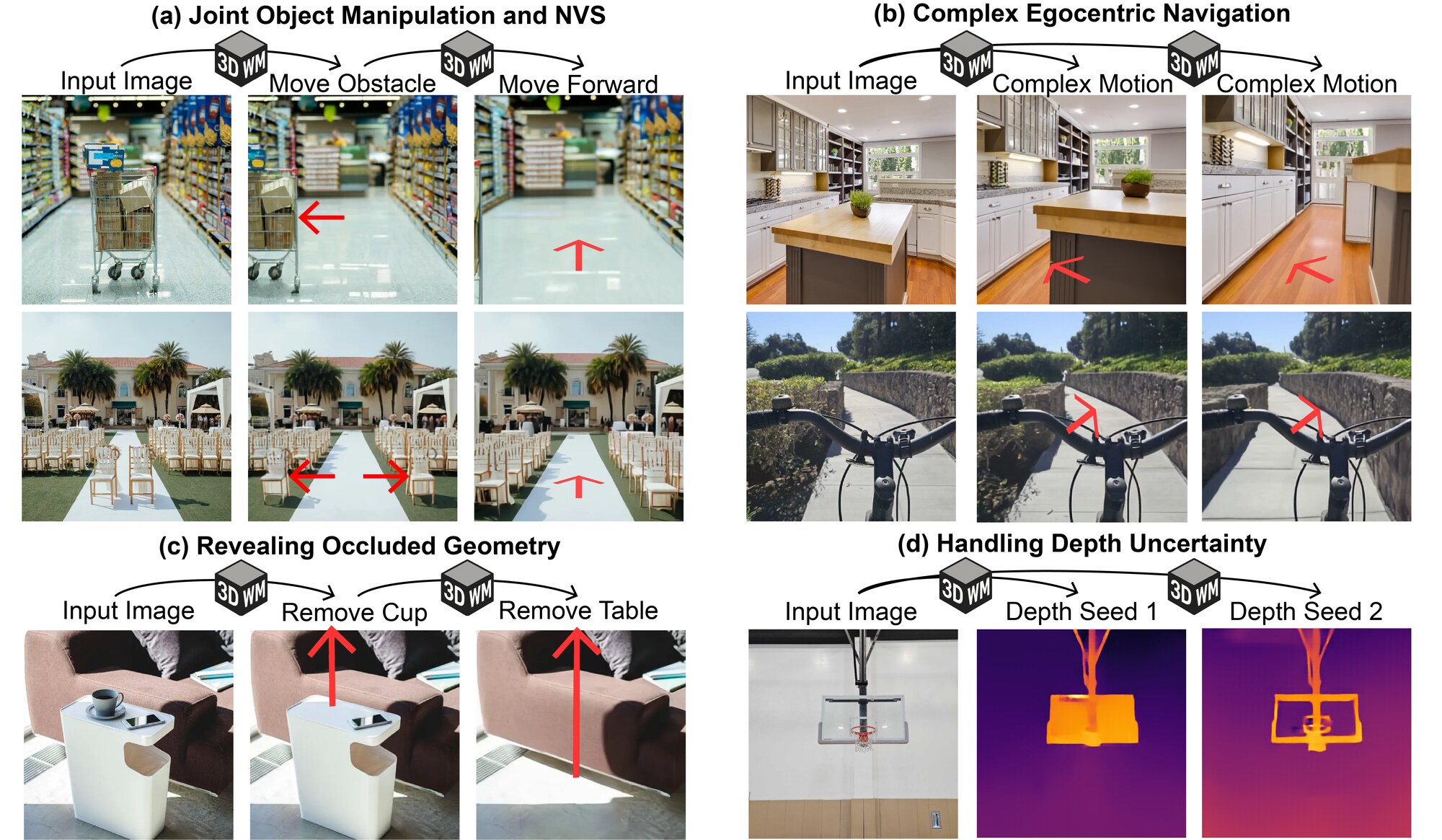
Novel View Synthesis. 3WM performs controllable novel view synthesis by conditioning on 2D optical-flow fields that encode how pixels move under a desired camera transformation. We estimate depth with an off-the-shelf model, unproject into a 3D point cloud, apply the rigid camera transformation, reproject, and use the resulting flow as the conditioning. The model generates the novel view while preserving object identity and scene consistency across camera motions.

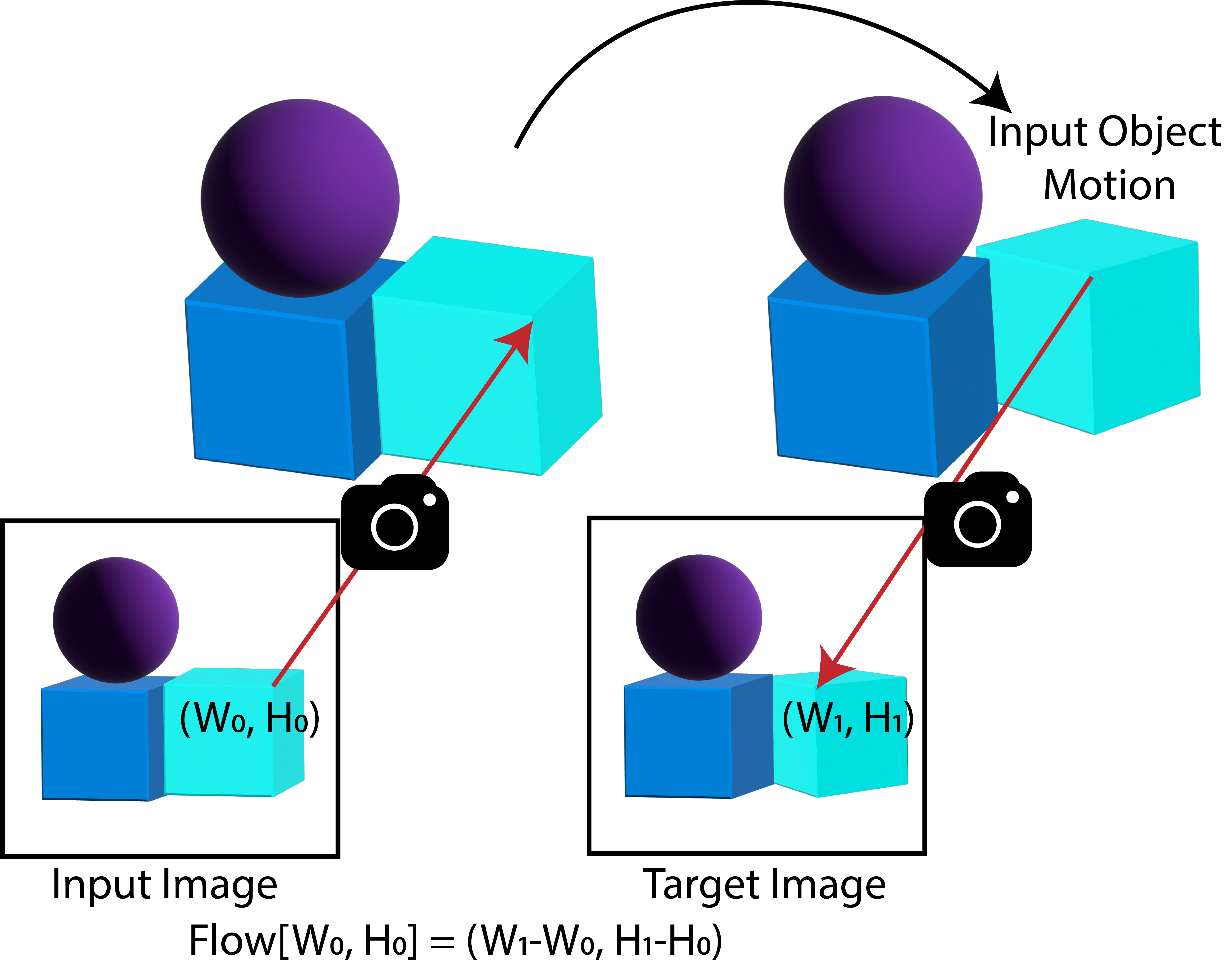
3D Object Manipulation. 3WM performs 3D object translation and rotation while preserving the background. We construct a flow field where the flow on the object surface encodes the 3D transformation and the background flow is set to zero, using SegmentAnything to isolate the object mask. The same pathway supports sparse-to-dense flow completion, so a sparse motion prompt can be turned into a dense object-motion flow and applied to generate the edited image.

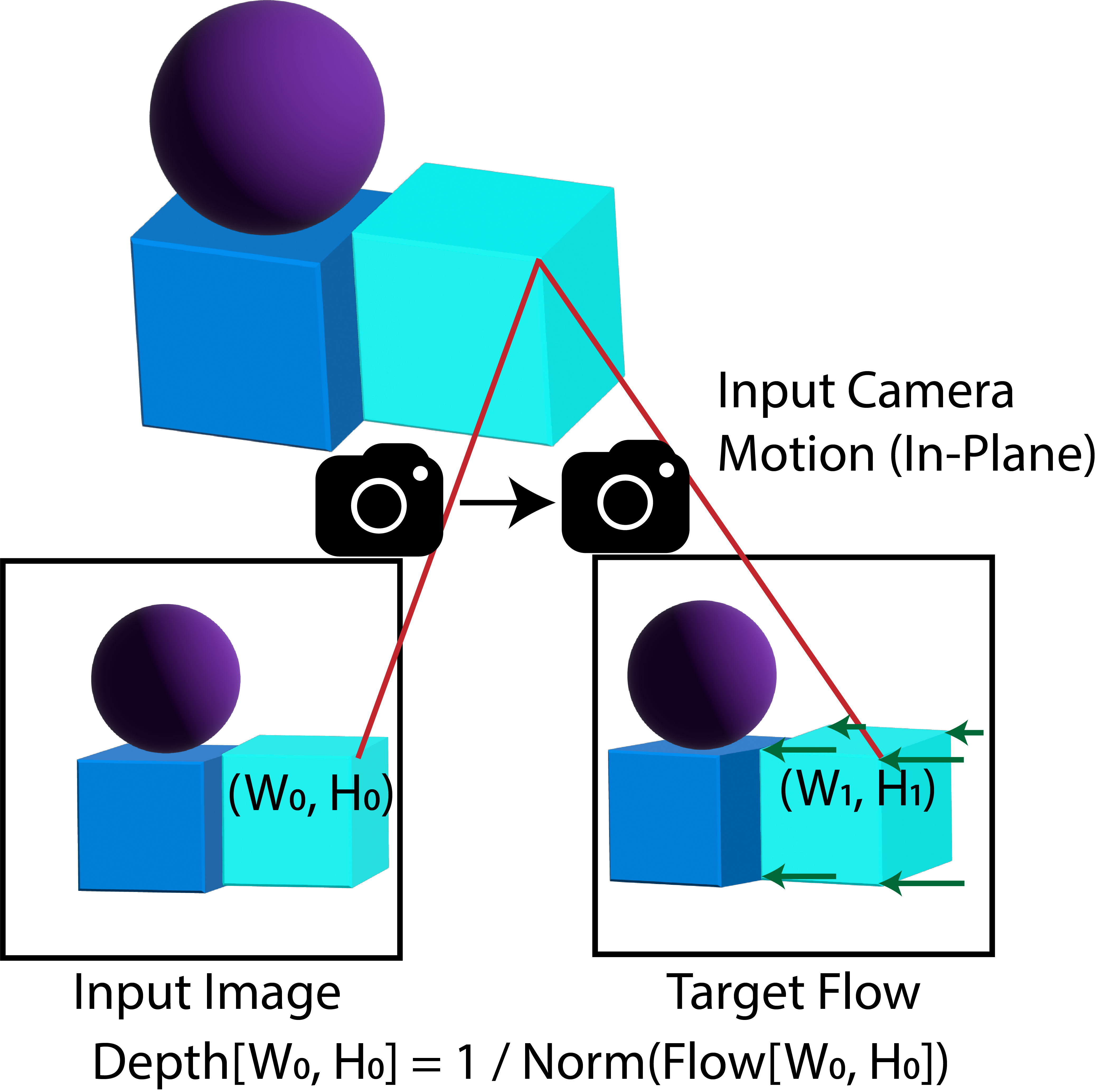
Self-Supervised Depth Estimation. 3WM estimates depth by prompting the camera-conditioned flow pathway: given an in-plane camera translation, the model predicts the induced optical flow, and depth follows from D ∝ 1/|F|. A simple downward camera translation is sufficient, and performance can be further improved by aggregating over multiple seeds. This approach learns depth cues from optical flow without any depth supervision during training.
